DDIA Chap3
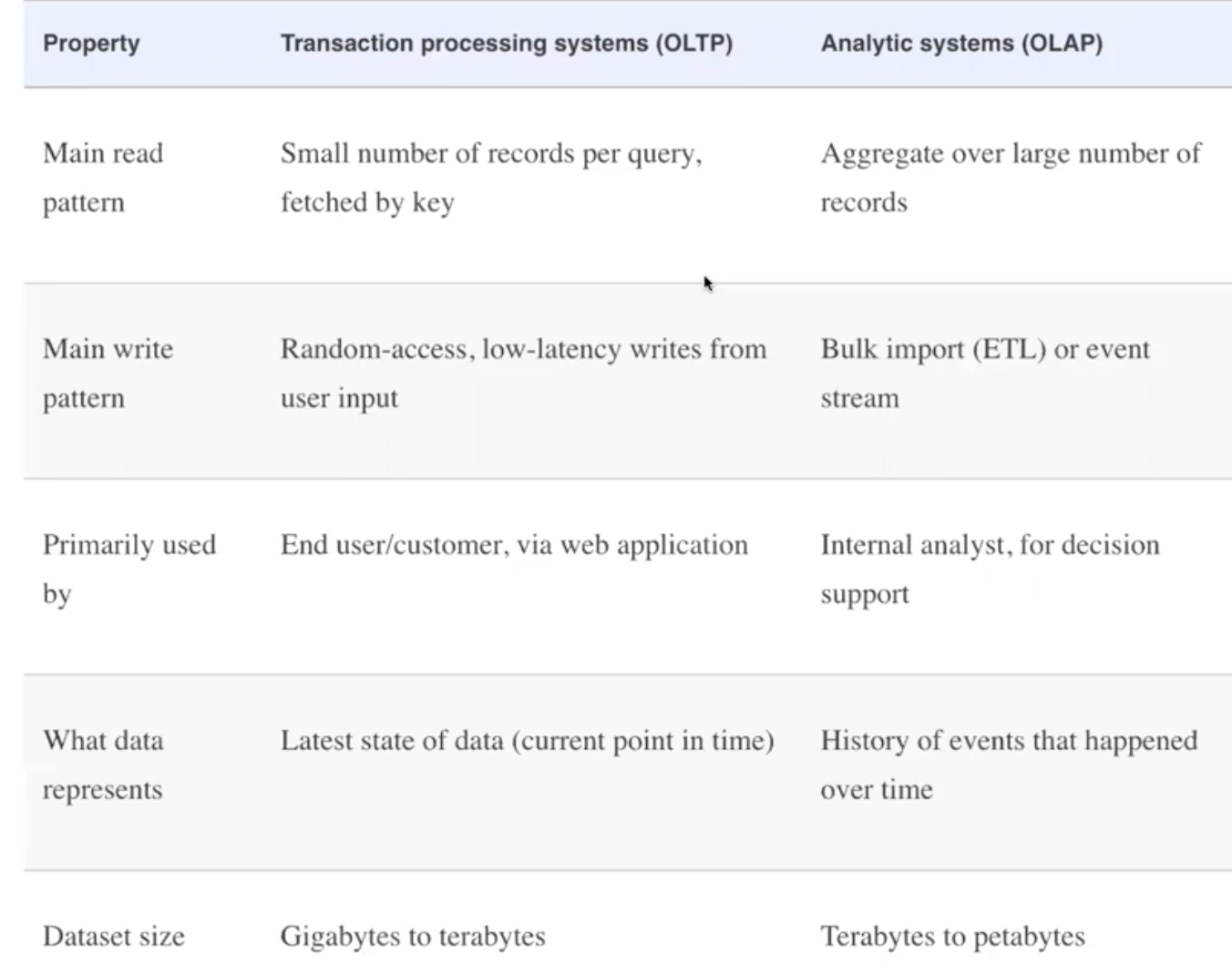
OLTP
-> Transaction, small data with CRUD small request; less data with CRUD bottlenack: locate data by indexing with low latency B tree -> LSMT
what’s DB?
- store data
- load data
Why index
- reduce seek time; from O(N) -> O(1)
- carefully select the index based on access pattern like read-write-ratio
- multi-field index, order matters for performance/ look up path; e.g. (lat, long) -> RTree(Postgres), geohash (fieldA, fieldB) -> index large-cardinality field first
in-memory hashmap; y log-structured file on disk:
| key | byte offset |
|---|---|
| 123 | 0 |
| 456 | 64 |
appending only; better performance
performing compaction and segment merging simultaneously
Further improvement:
- file format:
LSM Tree
- memtable: in-mem balanced tree
- memtable larger than the threshold; -> write to disk as SSTable
- read-request: mem -> most recent on-disk -> next-order segment
- background process: merging/compaction to combine segment files and discard overwrittenor deleted val
- bloom filter for non-existing keys: fast lookup existence, can be false positive.
- size tier or level compaction: how to handle crash?
- add write-ahead log; as memtable; duplication on-disk to restore the memtable.(WAL)
B Tree:
flat tree: 4 level -> 250TB data;
how to half-written record?
- WAL; when corruption; repair by WAL
- copy on write: copy both level -> modify -> swap; no cropped state better branching factor -> less level:
- more keys into a page
- keys on enough info
page can be anywhere on disk -> nearby layout
- leaf page -> nearby layout(sequentail order on disk), no need to lookup from parent page;
B+ Tree:
more opt:
Comparison
| LSMT | B Tree | |
|---|---|---|
| sequential write; 10 fast than random write, higher write throughput | ||
| Tiered storage, frequent update lookup faster | if in-mem cache, fast, o.w. slow | |
| better compression, less fregmentation | tree -> fregmentation | |
| lower write amplification -> compact SSTable files, rather than overwrite several pages in tree | COW, copy too much, amortized O(1), but 3 page copy in worest case | |
| compact process affecting ongoing read and write | no background process, so perf predictable | |
| key in multiple space, additional complexity to transaction isolation |
Index
- LSI/GSI
- Clustered index(all in mem) -> covered index(mix) -> only ref index(all in disk)
- multi-colum index: geohash or other concatenated index, KD tree/R Tree
- Fuzzy Search in Lucene
OLAP
-> scan all table; how to improve the processing throughput. when fetching more than half of data, indexing is not that important.
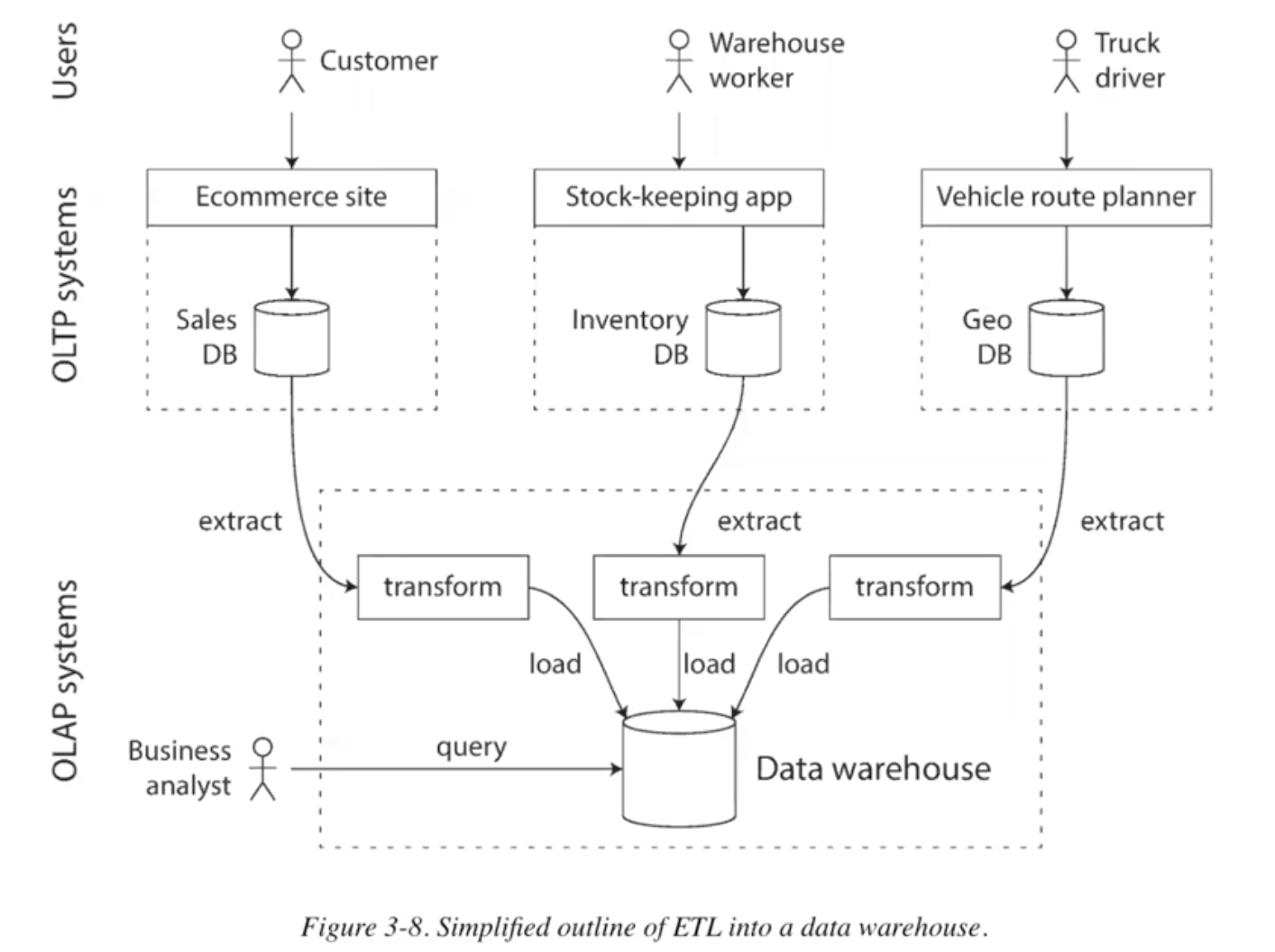
data lake v.s. data warehouse
- data warehouse well maintained, with indexewd; write by ETL(once a day), read-only from BA
- data lake, more garbage, not well organized.$$
Schema:
- in data warehous modelling, star schema(snowflake schema): fact(transaction) table and dimension(entity) table
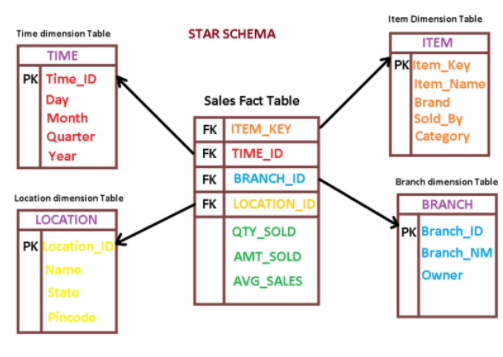
- fact table:
- contains: 1. all the primary keys of the dimension; 2. associated facts or measures(quantity sold, avg sales)
- dimension table:
- Dimension tables provides descriptive information for all the measurements recorded in fact table.
- Dimensions are relatively very small as comparison of fact table.
- Commonly used dimensions are people, products, place and time. ref:
- http://www.dataintegration.ninja/loading-star-schema-dimensions-facts-in-parallel/
- https://stackoverflow.com/questions/20036905/difference-between-fact-table-and-dimension-table
why column storage is a better fit
- fact table contains hundreds of column, usually in OLAP, only need 4-5 of them
- OLTP store the row/doc/entity as one continuous process, very inefficient in OLAP access pattern(4-5%)
- wide column DB like cassandra and HBase are not column oriented storage.
- HDFS, Hive is column storage DB
- compression methid: What is Parquet?
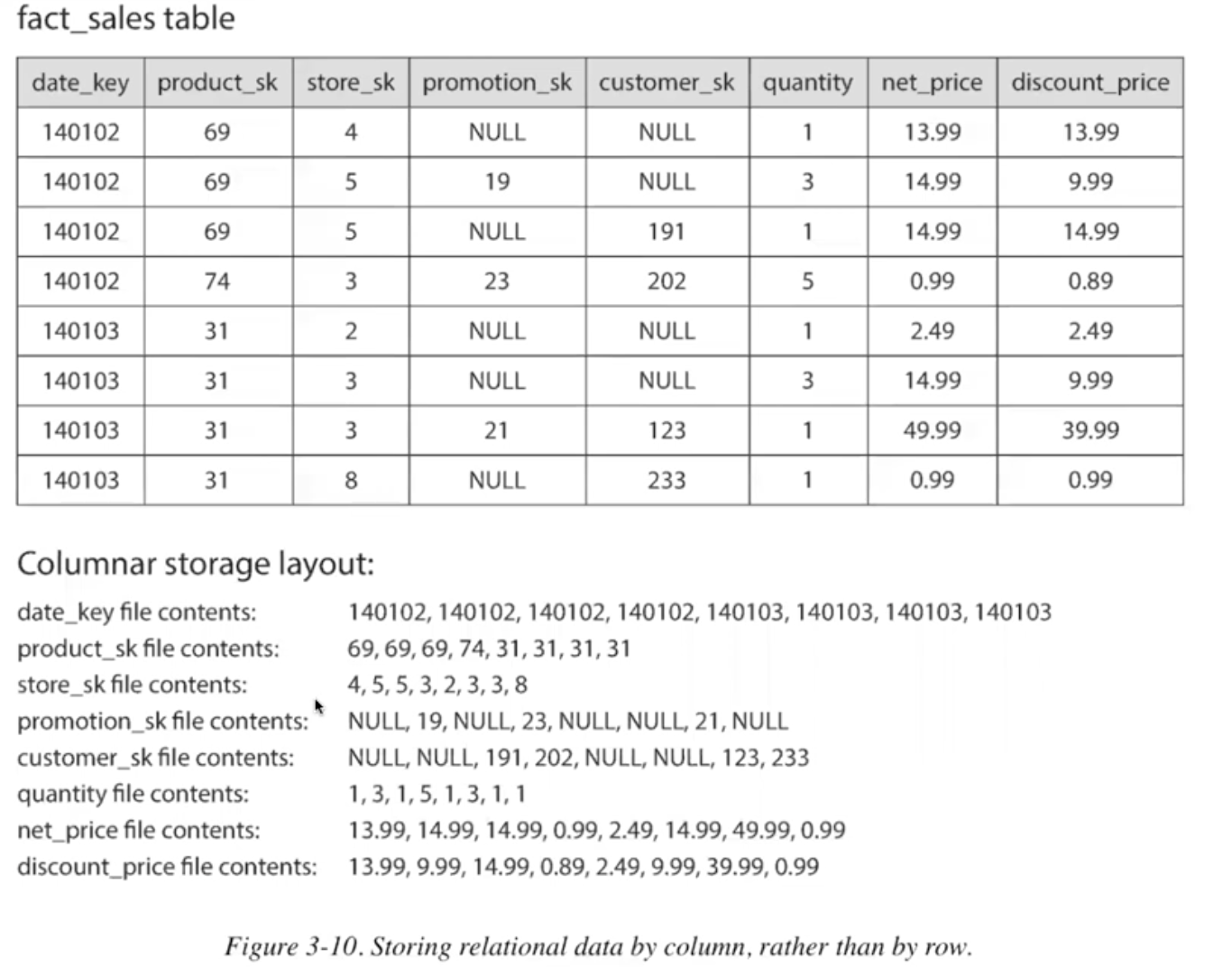
Column Compression
column values bitmap for each possible value run-length encoding 
requirement:
- additional row, needs to rewrite everything. -> O(N) very complex -> less write
Summary
- OLTP: a. user facing: huge amount of requests, b. only touch a small number of records in each query based on key c. storage engine use index to find data for the requested idx d. bottleneck: disk seek time
- OLAP(data warehouse) a. for BA, not by end users b. less query times, but each query demanding requires millions of records to be scanned in a short time c. compression: column-oriented storage d. bottleneck: disk bandwidth