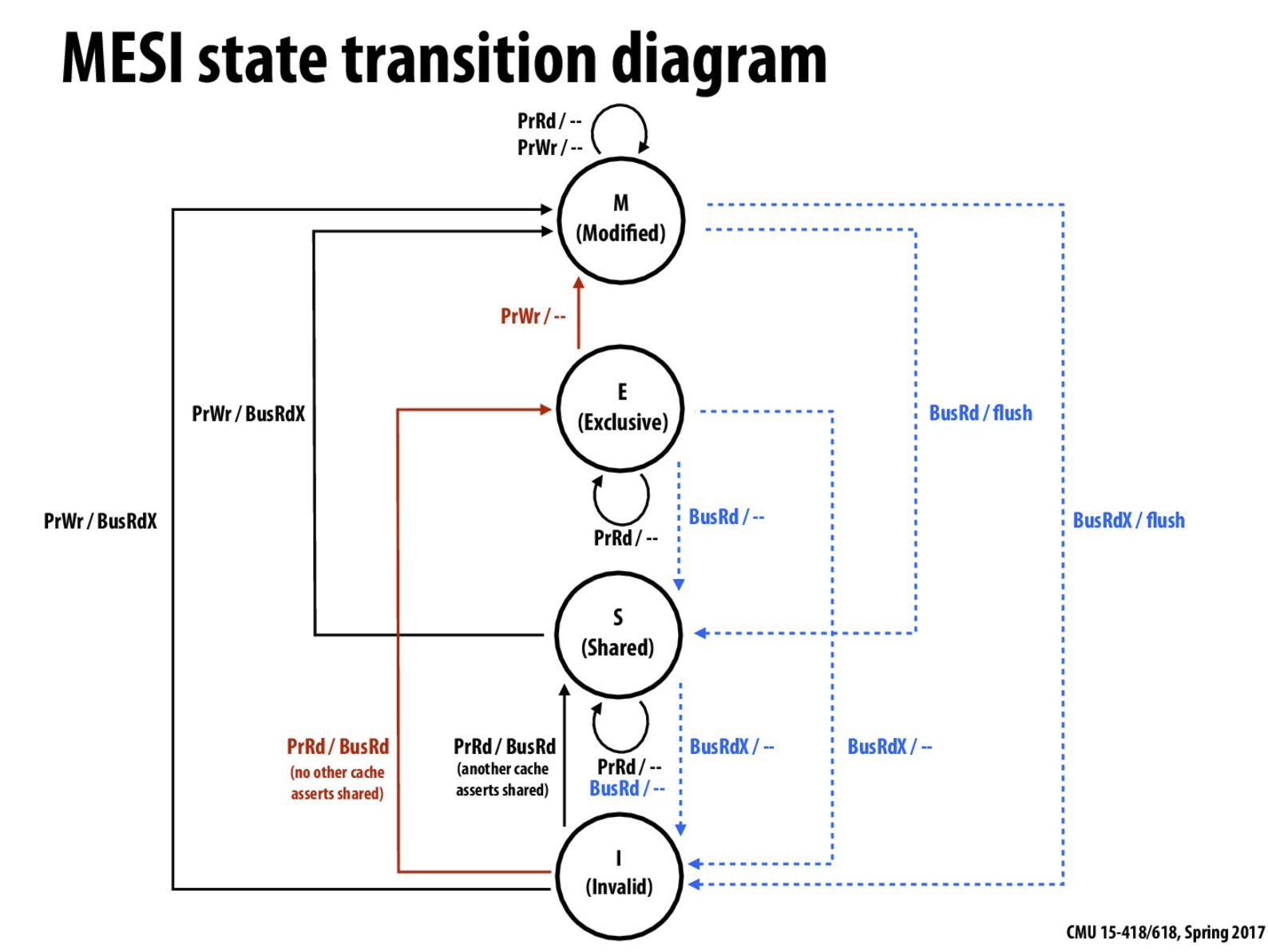
ref: MESI
 Cache Coherence
Cache Coherence
void foo_cpu0(void)
{
a = 1;
b = 1;
}
void bar_cpu1(void)
{
while (b==0) continue;
assert(a==1);
}
specs:
a, b - shared variables
a - CPU1 cache
b - CPU0 cache
foo - CPU0
bar - CPU1
because of storage buffer
- cpu0 execute a=1, a not in cache0, a=1 -> storage buffer, send read invalidate
- cpu0 execute b=1, b in cache0, write b=1 to cache0
- cpu1 execute while(b), b not in cache1, send read to cpu0 to get the cacheline, cpu0 send read response to cpu1 with b=1, cpu1 go out of while
-
cpu1 read a, a in cache1 is still 0, assert fail
- from step1, cpu1 receive *read invalida
write barrier for write: storebuffer FIFO write cache 保证写顺序的内存屏障发挥的作用是:把storebuffer变为FIFO的。只要storebuffer中有内容,之后的写操作都先写入storebuffer,而且按照先进先出的顺序写入cache;
read barrier for read: :处理Invalidate queue,把其中标记的cacheline实际置为无效
good page: https://zhuanlan.zhihu.com/p/283077214
to read: https://bartoszmilewski.com/2008/12/01/c-atomics-and-memory-ordering/ https://bartoszmilewski.com/2008/11/05/who-ordered-memory-fences-on-an-x86/ https://bartoszmilewski.wordpress.com/2008/08/04/multicores-and-publication-safety/